Équipe
Programme de réplication du génome et instabilité génomique





Présentation

Le programme de réplication doit s’adapter aux changements d’organisation de la chromatine associés à la différenciation cellulaire et au développement. Ses dérèglements peuvent nuire à la stabilité du génome et conduire à des mutations, des cancers ainsi qu’à de nombreuses autres maladies génétiques. Cependant, les règles qui régissent l’emplacement, l’efficacité et la période d’activation des origines de réplication chez l’homme sont encore très mal connues. Notre équipe utilise des approches génomiques pour étudier le programme spatio-temporel de réplication du génome humain et son impact sur la stabilité du génome.

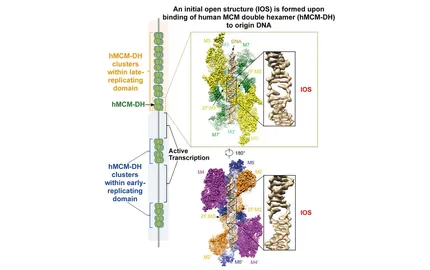
En collaboration avec des biologistes expérimentaux, nous avons développé une méthode (Repli-Seq) qui nous a permis de générer un des premiers profils de « timing » de réplication à haute résolution du génome humain (Fig. 1). L’étude des profils de timing de différents types cellulaires humains a montré que le génome est organisé en domaines de réplication associés à des unités structurales de la chromatine. Par des analyses des patrons de substitution nucléotidique, nous avons établi que le programme de réplication est un processus important de conduite le paysage mutationnel du génome dans les cellules normales et cancéreuses. Nous appliquons à présent la technique Repli-Seq en vu d’analyser de manière globale l’effet de stress réplicatifs sur la dynamique de réplication afin de comprendre comment les dérèglements du programme de réplication affectent la stabilité du génome, et en particulier, l’activité des sites fragiles communs (Fig 2).

Plus récemment, nous avons développé un nouvel outil Utilisant des algorithmes de machine learning. MnM permet d’automatiser l’analyse de ce paramètre temporel de la réplication de l’ADN. Les auteurs montrent ainsi, se basant sur des données générées sur plus de 119 000 cellules humaines, que des sous-populations hétérogènes de cellules peuvent être distinguées, ouvrant la voie vers une meilleurs compréhension des mécanismes impliqués dans le développement de tissus physiologiques et pathologiques.

Figure 3: Les variations du nombre de copies (CNV) des cellules uniques sont utilisées par un modèle d’apprentissage profond pour identifier l'état de réplication des cellules. Les cellules qui ne sont pas en phase de réplication sont ensuite regroupées à l'aide des algorithmes UMAP et DBSCAN afin de découvrir les sous-populations sous-jacentes. Enfin, les cellules en phase de réplication sont associées à ces sous-populations, ce qui permet de reconstruire trois sous-populations distinctes en fonction du temps de réplication, comme illustré par les profils CNV. Cette approche met en évidence l'hétérogénéité génomique dans les tissus tumoraux, en soulignant les altérations somatiques du nombre de copies et le processus d'aneuploïdie omniprésent lors de la tumorigenèse.
Notre étude du programme de réplication servira de base pour la compréhension de sa dynamique au cours du développement et du vieillissement, et permettra de mieux comprendre comment sa dérégulation contribue à de nombreuses pathologies.
La page GitHub de l’équipe : https://github.com/CL-CHEN-Lab.
La page Twitter/X: @TeamChenCurie